
Introducing InfraMatrix Global Systems Version 0.01
A new hyperscaler for the modern cloud

Introduction:
Cloud computing infrastructure today forces companies to choose between the convenience of public clouds like AWS and the control of private solutions like OpenStack. Each path requires tradeoffs - either sacrificing infrastructure control and cost optimization for ease of use, or investing heavily in complex private cloud maintenance.
InfraMatrix Global Systems(IGS) is designed to bring the ease of use of the public cloud with the finely-tuned control of the private cloud together in an environment that can run on any amount of hardware that a company or individual owns. Our hyperscaler provides a seamless cloud experience that runs on your own hardware and scales from small deployments to large enterprise infrastructure. The reason we are currently working on this hyperscaler is because we are building infrastructure software products, and we want to build a system that will scale to any amount of hardware in a simplified manner.
The source code and guide for running IGS is available here. Please note that this system is entirely experimental and not production-ready yet.
Architecture:
Before diving into the supported features, it would be helpful to first understand the current version’s system design and architecture. This is the current architecture of the hyperscaler:
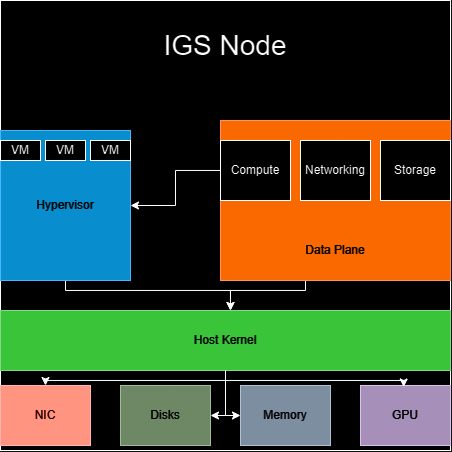
In this diagram, we see an IGS node that represents a server with several different components. We have various hardware resources like memory, NICs, disks, and GPUs. For the server’s operating system, we are using Ubuntu and that serves as the main coordinator for us being able to reach the hardware devices. We have a data plane which is what IGS represents currently, and that program talks to a hypervisor, in this case KVM, using QEMU for interfacing it and it talks to kernel in order to provision currently supported hardware, which are NICs and disks, currently.
As you can see, this is a monolithic software architecture making the hyperscaler not yet suitable for an enterprise production environment. The reason why it is not suitable is because a hyperscaler should be able to work from a single interface that will handle the communication between any amount of hardware. This monolith means that for every server that an organization has, it needs to install the hyperscaler on it, which is not feasible.
Subsystems:
Moving on we have 3 main subsystems that the hyperscaler has implemented, and they are compute, networking, and storage. Here is a brief overview of each and the technologies associated with them:
Compute - This serves as the main subsystem for providing VMs, containers, and serverless resources to applications. Currently, we are using KVM with QEMU to provision and launch the VMs.
Networking - This serves as the communication subsystem for compute resources to communicate with each other and external networks. Without this subsystem, we would not be able to push updates, install software, or run distributed systems. Currently, we are solely using QEMU’s SLiRP networking functionality to enable basic internet connectivity. A major problem with using SLiRP is that we can’t effectively server public key authentication for SSH, so the only way to communicate with the VMs running is effectively through serial, which can be a major issue.
Storage - This serves as the main memory subsystem for compute resources to save their state and data properly. Without this subsystem, we would not be able to make persistent changes or enable databases for services that are running on the node. Currently, IGS only supports provisioning and partitioning disks on the host and plugging partitions into VMs.
These are the main subsystems of IGS, currently. You may notice that there is an abundant reliance on existing systems that are mature like Linux and KVM. These mature OSSs provide us the ability to do whatever we want with our hardware, and it makes this project’s undertaking possible. Perhaps eventually it would make sense to write our own OS, hypervisor, networking/storage stacks, but these provide a ton of easy-to-use features for us now.
Main Functionalities:
Given that this project is quite immature, it only supports a couple main features:
Compute - On the compute side, we currently support creating, deleting, starting, stopping, and connecting to VMs over serial.
Networking - On the networking side, we currently support connecting VMs to internet
Storage - On the storage side, we currently support adding and removing, partitioning disks, and placing partitions into VMs.
These are baseline minimum functionalities for a hyperscaler Minimum-Viable-Product(MVP), but it is a good start. The system is quite buggy and thus not suitable for production environments yet, but it will be a lot closer once version 1.00 is released. This is a good segue into what to expect for version 1.
Version 1.00 Expected Features:
Version 1.00 is going to be a large release for the hyperscaler and make a lot of progress towards making it production ready. These are the improvements that will be made to the hyperscaler and its subsystems:
Testing - Create integration tests to validate all paths for the hyperscaler.
Compute - Provide a cleaner way to produce a golden VM image, be it serving it on the internet or autogeneration scripts that will produce the image in an automated manner instead of having to manually create it on the node.
Networking - Use Open vSwitch to connect VMs directly to Linux’s networking stack in a cleaner manner than using SLiRP to enable critical features like SSH and enable Security infrastructure in version 2.00.
Security - Enable SSH only communication. Isolate VM networking interfaces.
Observability - Enable Prometheus and Grafana metrics for capturing performance data for the node and the subsystems.