
How to run deepseek-r1 locally
A basic guide for setting up and running deepseek's r1 model

Recently, High-Flyer - a Chinese hedge fund published an LLM model that delivers similar performance to OpenAI’s ChatGPT-o1 and Anthropic’s Claude-Sonnet3.5 model. This model is unique because it can be run locally on your own consumer graphics hardware, making AI accessible to anyone with a decent GPU.
This is a guide for getting deepseek-r1 up and running on your system. Make sure that you have a system with a GPU(s) that have a total of around 16 GB of VRAM to make it feasible to run the model.
Before starting, make sure you have the relevant drivers for your GPUs. I am running Nvidia currently, so I have the drivers and CUDA toolkit installed.
1: You must first install a platform like ollama in order to pull the model and start inferencing on it. Follow these steps to install ollama:
For Mac and Ubuntu and Windows Subsystem For Linux, do the following:
curl -fsSL https://ollama.com/install.sh | shThis will install ollama.
2: Next, you need to run ollama’s backend in order to inference on it:
On the various platforms, you can run:
ollama serveand that should allow you to create another terminal to run deepseek.
On Linux systems running systemd, you can run:
sudo systemctl start ollamaAfter doing this you should see something like the following:
when you do ollama serve, or
when running systemctl to launch ollama service.
Once you have these, we can finally start inferencing!
3: Pull and run the deepseek model
For this step we are going to run the model locally. There are several models with varying amounts of parameters. The goal is the pick the best bang-for-the-buck model to run on your hardware. Here is a ranking of the models and their sizes:
1.5b version (smallest)
8b version
14b version
32b version
70b version
671b version (biggest)
There are a lot of different variations of r1, so here is a general breakdown to the best of my knowledge:
Use 1.5b, 8b, or 14b if you have around 16 GB of VRAM on your system. These are the economy models that will get the job done, but they are not the smartest.
Use 32b if you have around 32 GB of VRAM. You might actually need more VRAM, so running a 32GB GPU will probably cut it close.
Use 70b if you have something like an A100, and you probably need to run several state-of-the-art cards to run the 671b parameter model.
These are just guesstimates based off my experience using the 14b and smaller models on my GTX 1080s. I will show you how to determine which model is best for your system now.
4: Running the model
For actually running the model, open a terminal and run the following:
ollama run deepseek-r1:8bThis will kick off the process for ollama to pull the model and run it locally. To determine if your hardware is capable, run the folllowing in another terminal assuming you have Nvidia GPUs:
nvidia-smiYou will get an output like the following:
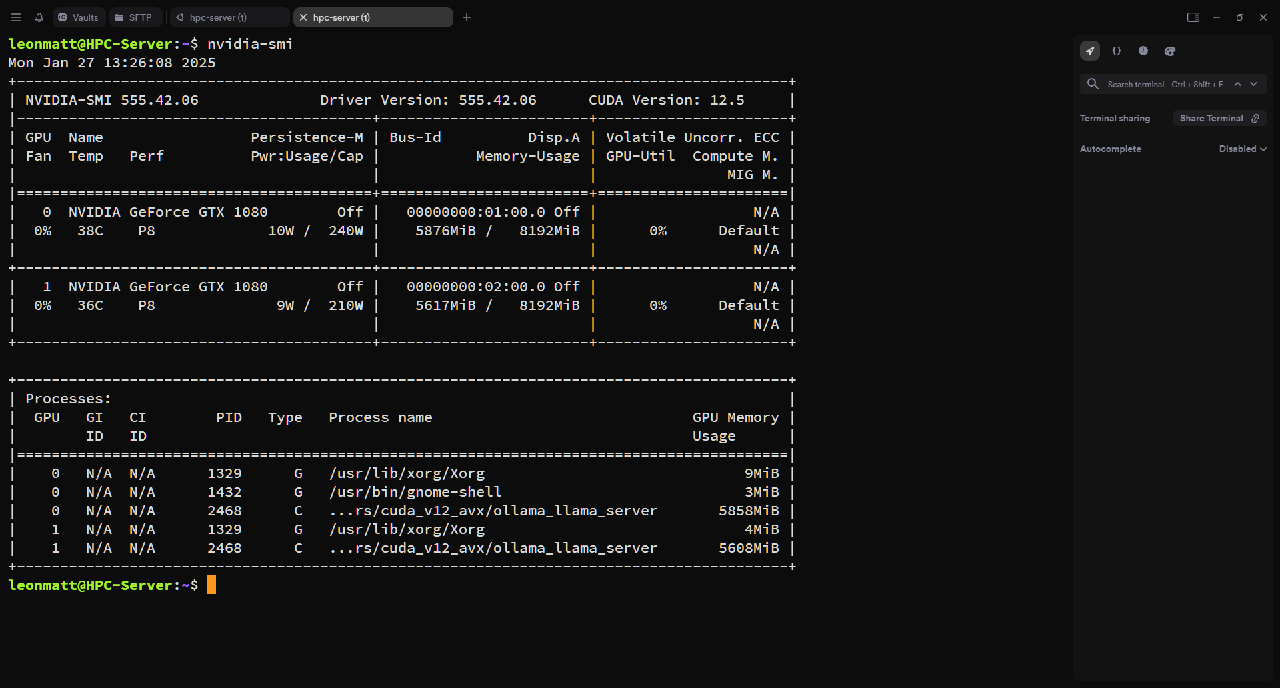
Notice that in my case I have dual GTX 1080s running, and they currently have the 14b model loaded. This model is the highest I can run with without overloading my GPUs.
If you have multiple GPUs, run the following command to use both in parallel for inferencing:
CUDA_VISIBLE_DEVICES=0,1 ollama run deepseek-r1:14b
Once you have completed these steps, you should be able to send a message and now you have the best AI running locally!
For an example, I gave it the following prompt: “Write a simple C++ hello world program” and it gave me the following output:
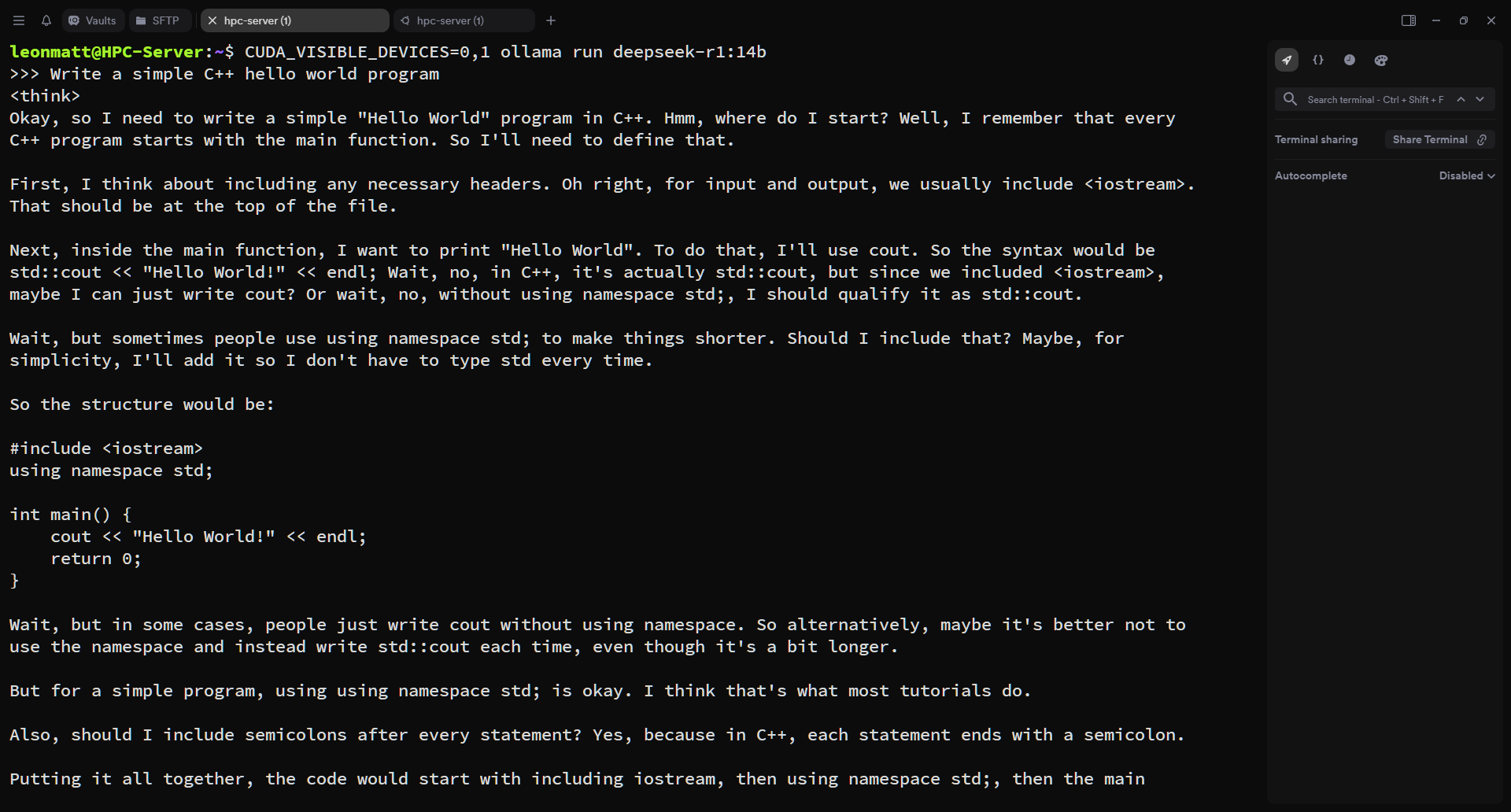
Enjoy!